Creating an AI Agent-Based System with LangGraph: Adding Persistence and Streaming (Step by Step Guide)


In our previous tutorial, we built an AI agent capable of answering queries by surfing the web. However, when building agents for longer-running tasks, two critical concepts come into play: persistence and streaming. Persistence allows you to save the state of an agent at any given point, enabling you to resume from that state in future interactions. This is crucial for long-running applications. On the other hand, streaming lets you emit real-time signals about what the agent is doing at any moment, providing transparency and control over its actions. In this tutorial, we’ll enhance our agent by adding these powerful features.
Setting Up the Agent
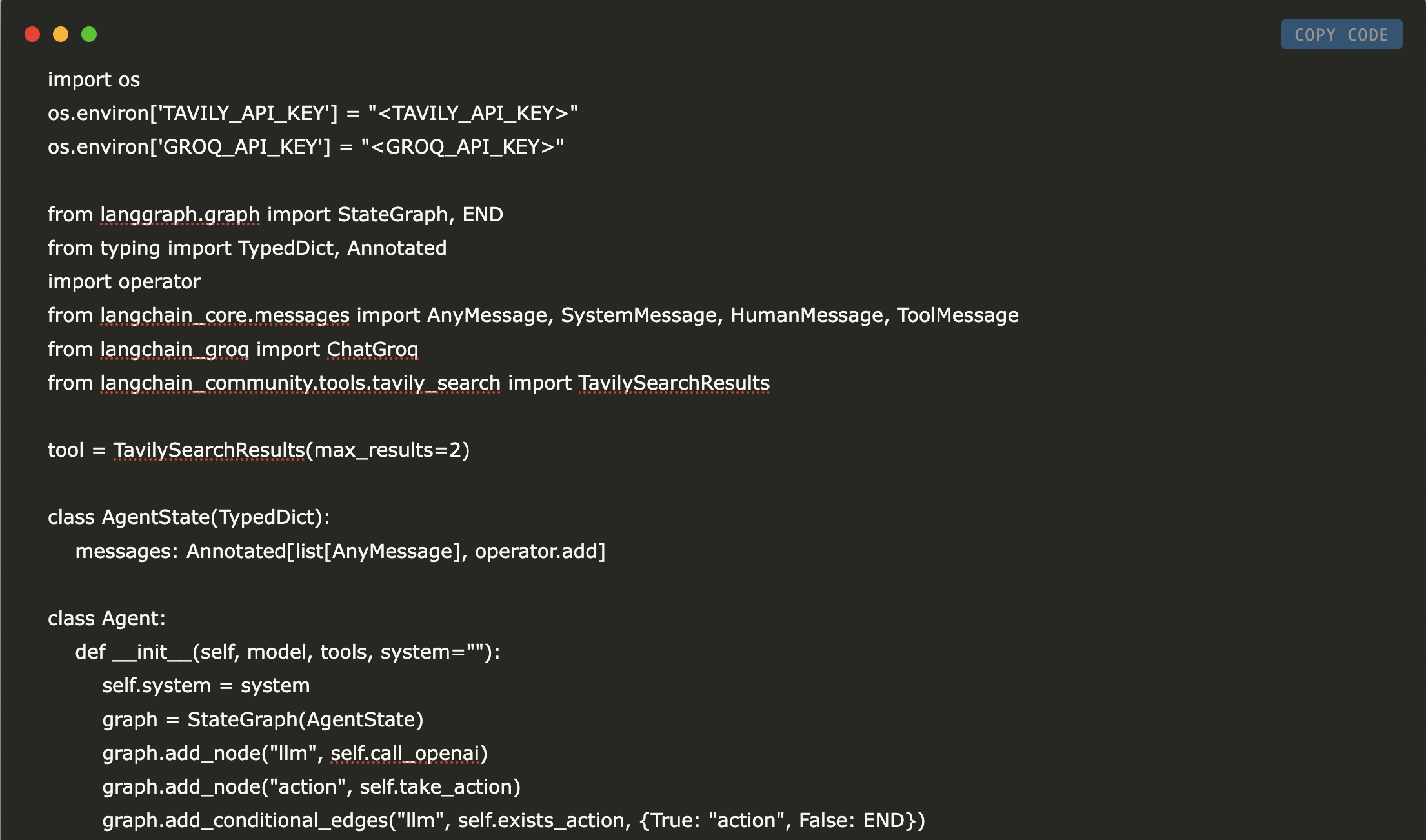
Let’s start by recreating our agent. We’ll load the necessary environment variables, install and import the required libraries, set up the Tavily search tool, define the agent state, and finally, build the agent.
os.environ[‘TAVILY_API_KEY’] = “<TAVILY_API_KEY>”
os.environ[‘GROQ_API_KEY’] = “<GROQ_API_KEY>”
from langgraph.graph import StateGraph, END
from typing import TypedDict, Annotated
import operator
from langchain_core.messages import AnyMessage, SystemMessage, HumanMessage, ToolMessage
from langchain_groq import ChatGroq
from langchain_community.tools.tavily_search import TavilySearchResults
tool = TavilySearchResults(max_results=2)
class AgentState(TypedDict):
messages: Annotated
class Agent:
def __init__(self, model, tools, system=””):
self.system = system
graph = StateGraph(AgentState)
graph.add_node(“llm”, self.call_openai)
graph.add_node(“action”, self.take_action)
graph.add_conditional_edges(“llm”, self.exists_action, {True: “action”, False: END})
graph.add_edge(“action”, “llm”)
graph.set_entry_point(“llm”)
self.graph = graph.compile()
self.tools = {t.name: t for t in tools}
self.model = model.bind_tools(tools)
def call_openai(self, state: AgentState):
messages = state[‘messages’]
if self.system:
messages = [SystemMessage(content=self.system)] + messages
message = self.model.invoke(messages)
return {‘messages’: [message]}
def exists_action(self, state: AgentState):
result = state[‘messages’][-1]
return len(result.tool_calls) > 0
def take_action(self, state: AgentState):
tool_calls = state[‘messages’][-1].tool_calls
results = []
for t in tool_calls:
print(f”Calling: {t}”)
result = self.tools[t[‘name’]].invoke(t[‘args’])
results.append(ToolMessage(tool_call_id=t[‘id’], name=t[‘name’], content=str(result)))
print(“Back to the model!”)
return {‘messages’: results}
Adding Persistence
To add persistence, we’ll use LangGraph’s checkpointer feature. A checkpointer saves the state of the agent after and between every node. For this tutorial, we’ll use SqliteSaver, a simple checkpointer that leverages SQLite, a built-in database. While we’ll use an in-memory database for simplicity, you can easily connect it to an external database or use other checkpoints like Redis or Postgres for more robust persistence.
import sqlite3
sqlite_conn = sqlite3.connect(“checkpoints.sqlite”,check_same_thread=False)
memory = SqliteSaver(sqlite_conn)
Next, we’ll modify our agent to accept a checkpointer:
def __init__(self, model, tools, checkpointer, system=””):
# Everything else remains the same as before
self.graph = graph.compile(checkpointer=checkpointer)
# Everything else after this remains the same
Now, we can create our agent with persistence enabled:
You are allowed to make multiple calls (either together or in sequence). \
Only look up information when you are sure of what you want. \
If you need to look up some information before asking a follow-up question, you are allowed to do that!
“””
model = ChatGroq(model=”Llama-3.3-70b-Specdec”)
bot = Agent(model, [tool], system=prompt, checkpointer=memory)
Adding Streaming
Streaming is essential for real-time updates. There are two types of streaming we’ll focus on:
1. Streaming Messages: Emitting intermediate messages like AI decisions and tool results.
2. Streaming Tokens: Streaming individual tokens from the LLM’s response.Let’s start by streaming messages. We’ll create a human message and use the stream method to observe the agent’s actions in real-time.
thread = {“configurable”: {“thread_id”: “1”}}
for event in bot.graph.stream({“messages”: messages}, thread):
for v in event.values():
print(v[‘messages’])
Final output: The current weather in Texas is sunny with a temperature of 19.4°C (66.9°F) and a wind speed of 4.3 mph (6.8 kph)…..
When you run this, you’ll see a stream of results. First, an AI message instructing the agent to call Tavily, followed by a tool message with the search results, and finally, an AI message answering the question.
Understanding Thread IDs
The thread_id is a crucial part of the thread configuration. It allows the agent to maintain separate conversations with different users or contexts. By assigning a unique thread_id to each conversation, the agent can keep track of multiple interactions simultaneously without mixing them up.
For example, let’s continue the conversation by asking, “What about in LA?” using the same thread_id:
thread = {“configurable”: {“thread_id”: “1”}}
for event in bot.graph.stream({“messages”: messages}, thread):
for v in event.values():
print(v)
Final output: The current weather in Los Angeles is sunny with a temperature of 17.2°C (63.0°F) and a wind speed of 2.2 mph (3.6 kph) ….
The agent infers that we’re asking about the weather, thanks to persistence. To verify, let’s ask, “Which one is warmer?”:
thread = {“configurable”: {“thread_id”: “1”}}
for event in bot.graph.stream({“messages”: messages}, thread):
for v in event.values():
print(v)
Final output: Texas is warmer than Los Angeles. The current temperature in Texas is 19.4°C (66.9°F), while the current temperature in Los Angeles is 17.2°C (63.0°F)
The agent correctly compares the weather in Texas and LA. To test if persistence keeps conversations separate, let’s ask the same question with a different thread_id:
thread = {“configurable”: {“thread_id”: “2”}}
for event in bot.graph.stream({“messages”: messages}, thread):
for v in event.values():
print(v)
Output: I need more information to answer that question. Can you please provide more context or specify which two things you are comparing?
This time, the agent gets confused because it doesn’t have access to the previous conversation’s history.
Streaming Tokens
To stream tokens, we’ll use the astream_events method, which is asynchronous. We’ll also switch to an async checkpointer.
async with AsyncSqliteSaver.from_conn_string(“:memory:”) as checkpointer:
abot = Agent(model, [tool], system=prompt, checkpointer=checkpointer)
messages = [HumanMessage(content=”What is the weather in SF?”)]
thread = {“configurable”: {“thread_id”: “4”}}
async for event in abot.graph.astream_events({“messages”: messages}, thread, version=”v1″):
kind = event[“event”]
if kind == “on_chat_model_stream”:
content = event[“data”][“chunk”].content
if content:
# Empty content in the context of OpenAI means
# that the model is asking for a tool to be invoked.
# So we only print non-empty content
print(content, end=”|”)
This will stream tokens in real-time, giving you a live view of the agent’s thought process.
Conclusion
By adding persistence and streaming, we’ve significantly enhanced our AI agent’s capabilities. Persistence allows the agent to maintain context across interactions, while streaming provides real-time insights into its actions. These features are essential for building production-ready applications, especially those involving multiple users or human-in-the-loop interactions.
In the next tutorial, we’ll dive into human-in-the-loop interactions, where persistence plays a crucial role in enabling seamless collaboration between humans and AI agents. Stay tuned!
References:
- (DeepLearning.ai) https://learn.deeplearning.ai/courses/ai-agents-in-langgraph
Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 75k+ ML SubReddit.
🚨 Meet IntellAgent: An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System (Promoted)
Vineet Kumar is a consulting intern at MarktechPost. He is currently pursuing his BS from the Indian Institute of Technology(IIT), Kanpur. He is a Machine Learning enthusiast. He is passionate about research and the latest advancements in Deep Learning, Computer Vision, and related fields.
